

模型的工作原理与deepseek 做个对比,并深入解析推理模型的原理
好的,我们来深入对比一下模型的工作原理,特别是DeepSeek模型,并解析推理模型的原理。
首先,要理解DeepSeek模型,我们需要知道它是一种大型语言模型(LLM)。 大语言模型,正如其名,是能够理解和生成人类语言的超级智能文本生成器。它们通过学习海量的文本数据来掌握语言的规律,从而能够进行文本生成、翻译、问答等多种自然语言处理任务。 aitoolssme.com 为了更好地服务于各种需求,市面上涌现了许多领先的大语言模型,各有千秋。 ai-pro.org, mindsdb.com, leewayhertz.com 选择最合适的LLM需要考虑延迟、成本、性能和上下文窗口等关键参数。 medium.com/@genai.works
DeepSeek 的架构与工作原理
DeepSeek R1 模型尤其引人注目,它建立在两个基础支柱之上:混合专家 (MoE) 框架 和 先进的 Transformer 设计。 geeksforgeeks.org 这是一种混合架构,旨在提升模型的性能和效率。
-
Transformer 架构: Transformer 模型是现代 LLM 的基石。 您可能已经熟悉 Transformer 模型,它在神经机器翻译等任务中表现出色。 machinelearningmastery.com DeepSeek 同样采用了 Transformer 架构,这使其具备了处理长序列和捕捉上下文信息的能力。
-
混合专家 (MoE) 架构: DeepSeek R1 的一个关键创新是采用了混合专家 (MoE) 架构。 modular.com, encord.com MoE 是一种神经网络设计,它整合了多个“专家”子模型,每个子模型 специализируется 在输入数据的不同方面。 modular.com DeepSeek R1 拥有 6710 亿参数,但得益于 MoE 架构,每个 token 的处理实际上只激活相当于 370 亿参数的子网络。 medium.com/@isaakmwangi2018 这意味着模型能够在保持高性能的同时,显著减少计算成本和资源需求。对于不同的输入,MoE 架构会选择性地激活不同的参数子集进行处理。 encord.com
-
Tokenizer: DeepSeek 在 tokenizer 上也进行了优化。它使用了一个 102k 的 tokenizer。 planetbanatt.net 更大的 tokenizer 通常能够更有效地编码文本,从而提升模型性能。
推理 (Inference) 模型的原理
推理 (Inference) 是指在模型训练完成后,使用训练好的模型来处理新的输入并生成输出的过程。 medium.com/@sachinsoni600517 对于 Transformer 模型来说,推理过程与训练过程有所不同。 youtube.com
-
Transformer 的推理过程: 当 Transformer 模型进行推理时,它会接收输入序列(例如,一段文本),并逐个 token 地生成输出序列。 这个过程通常是自回归的,意味着模型会根据之前生成的 token 来预测下一个 token。
- 输入编码: 首先,输入文本会被 tokenizer 转换为 token 序列,并经过 Embedding 层转换为向量表示。
- Transformer 层处理: 这些向量表示会输入到 Transformer 层(包括自注意力机制和前馈网络)进行处理,模型会根据输入上下文计算每个 token 的表示。
- 输出预测: 模型会使用最后一个 Transformer 层的输出,通过线性层和 Softmax 函数来预测下一个 token 的概率分布。
- Token 生成: 根据概率分布,模型会选择概率最高的 token 作为输出,或者使用采样等方法来增加生成的多样性。
- 迭代生成: 将生成的 token 添加到输入序列的末尾,重复步骤 1-4,直到生成结束符 token 或达到最大长度限制。
-
DeepSeek 的推理特点 (MoE 的影响): DeepSeek 在推理时,MoE 架构会发挥关键作用。 对于每个输入的 token,路由机制会决定激活哪些“专家”子模型。 这意味着在推理过程中,只有一部分参数会被激活,从而提高了推理效率。 虽然 DeepSeek 模型整体参数量巨大,但在实际推理时,每个 token 只需计算相当于 370 亿参数的计算量,这大大降低了计算需求,使得 DeepSeek 能够在保证模型性能的同时,实现更快的推理速度和更低的资源消耗。
-
推理优化: 为了进一步提升 Transformer 模型的推理性能,可以进行各种优化,例如使用 Intel CPU 上的 oneDNN 库来优化 Transformer 推理,从而显著提高吞吐量和降低延迟。 intel.com
总结与对比
总而言之,DeepSeek 模型在 Transformer 架构的基础上,创新性地引入了混合专家 (MoE) 架构。 这种架构使得 DeepSeek 能够在拥有巨大参数量的同时,在推理时保持高效。 与传统的 Transformer 模型相比,DeepSeek 在推理过程中更加高效,因为它只需要激活部分参数。 这使得 DeepSeek 在性能和效率之间取得了良好的平衡,使其成为一个非常有竞争力的 LLM。 理解 DeepSeek 的架构和推理原理,有助于我们更好地理解现代 LLM 的发展趋势和技术特点。
DeepSeek 的 MoE 架构具体是如何工作的?
DeepSeek 的 MoE(Mixture-of-Experts,混合专家)架构是一种能够在极大参数量系统中精选性激活部分专家网络,从而达到兼顾模型容量和计算效率的创新设计。下面我们详细解析 DeepSeek MoE 架构的工作原理,以及它是如何实现专家化分工、路由机制和共享专家隔离等关键技术的。
──────────────────────────────
【一、DeepSeek MoE 架构的基本思想】
-
大规模模型的挑战
在大语言模型迅速发展的时代,参数量往往达到数百亿甚至上千亿,为了在模型规模扩展的同时保持推理和训练的高效性,研究者们逐步探索采用 MoE 架构。MoE 将整个模型参数划分成多个“专家”模块(子模型),每个专家模块专注处理输入数据的某一部分信息,这样能在很大程度上缓解计算资源的消耗问题。(参见 (DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture …)) -
专家化的基本机制
在 MoE 架构中,并非所有专家都在每一次前向传播中全部激活,而是由一个路由器(Router)模块按照给定的算法选择最适合当前输入的若干专家子网络进行激活。这样,尽管整个模型的参数数量庞大,但每个 token 的实际计算仅涉及激活部分专家参数,大大降低了计算开销。(参见 (Mixture of Experts Explained – Hugging Face))
──────────────────────────────
【二、DeepSeek MoE 的核心技术与优化】
-
精细化专家分割(Fine-Grained Expert Segmentation)
DeepSeek MoE 在专家划分上采用了精细化的分割策略,每个专家模块针对数据中的不同隐含模式进行专门化训练。这样,当路由器对输入数据做出判断时,可以将特定领域或特定模式的 token 分流到最适合的专家,这种专门化设计不仅能提高模型对复杂任务的处理能力,还能使每个专家在其擅长领域内达到更优性能。(参见 (deepseek-ai/DeepSeek-MoE: DeepSeekMoE – GitHub)) -
共享专家隔离(Shared Experts Isolation)
除了精细的专家分割,DeepSeek 架构还引入共享专家隔离策略。这一策略的目的在于防止不同输入之间的干扰,同时保证在多个任务中复用部分计算资源。共享专家隔离机制确保了即使同一专家在不同的输入之间被调用,也能够保持其独特性和稳定性,从而在不同任务或不同场景中表现一致。(参见 (DeepSeek and the Power of Mixture of Experts (MoE))) -
路由机制的设计
路由器在 MoE 中起决定性作用,其任务是根据输入 token 的特征,动态决定激活哪些专家,以及如何分配输入在各个专家间的任务。理想的路由策略应满足以下要求:
• 高效分流:能够快速判断输入特征,将信息尽可能准确地分派给最适合的专家。
• 负载均衡:有效地避免某几个专家过度工作而其他专家闲置,从而维持整体计算资源的高效利用。
• 稳定性:路由算法在面对变化多端的输入时依然能保持较高的稳定性,防止训练和推理时的不确定性。(参见 (Routers in Vision Mixture of Experts: An Empirical Study))
DeepSeek 的 MoE 路由器一般用基于软决策(Softmax 或 ReLU 路由,如 ReMoE 就是一种变种,它使用完全可微分的 ReLU 路由)的策略,以便在反向传播中保持梯度流通,使得整个系统能够端到端地联合训练。这样设计使得模型更加灵活,并且在大规模参数情况下,依然能保持良好的训练稳定性。(参见 (ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing))
──────────────────────────────
【三、DeepSeek MoE 在具体推理过程中的应用】
-
推理时部分激活
在推理阶段,尽管 DeepSeek 总模型参数量可能高达 6710 亿,但其 MoE 架构仅激活与当前 token 最相关的部分专家。例如,有报道表明每个 token 仅需要激活相当于 370 亿参数的子网络计算,这种部分激活策略既保证了模型推理过程中能够充分利用海量参数的效果,又极大提升了推理速度和降低了资源消耗。(参见 (DeepSeek R1: All you need to know – Fireworks AI)) -
专家路由与序列生成
在自回归文本生成中,每一个新生成的 token 都需要经过路由器的判断决定最佳专家组合。流程大致为:
• 输入编码:首先,将输入文本通过 tokenizer 转换为 token 序列。DeepSeek 采用了一个大规模的 102k tokenizer,这种大词汇表能使得模型捕捉更多的微妙语义差异。(参见 (DeepSeekMoE: Bridging Efficiency and Capacity in Large …))
• 路由与专家激活:每个 token 的特征输入到路由模块,路由器依据特征决定激活哪些专家模块,使得这部分计算任务仅限于最匹配的子网络。
• 专家处理:激活后的专家单独计算,提取 token 的深层语义信息,并经过后续 Transformer 层(如多头注意力、前馈网络等)处理。
• 输出生成:最后,将处理结果合并,通过线性层和 Softmax 层生成下一个 token 的概率分布,然后根据策略(贪心、采样等)生成输出。
这种基于 MoE 的推理流程在有效利用计算资源的同时,还能动态适应复杂文本生成任务中的多样性需求。(参见 (Cerebras Launches World’s Fastest DeepSeek R1 Llama-70B …))
──────────────────────────────
【四、DeepSeek MoE 架构的优势与挑战】
-
优势
• 高容量与低计算成本的完美平衡:通过 MoE 架构,每个 token 的计算仅涉及一部分专家网络,使得海量参数可以同时维持高效推理。
• 更高的模型灵活性:精细的专家分割和共享专家隔离保证了模型在不同领域任务中的表现稳定,且拓展性更强。
• 动态路由提升了上下文敏感性:路由器的动态决策使得模型能够捕捉到极其细腻的语义差异,从而在内容生成、逻辑推理和复杂任务上都表现出色。(参见 (DeepSeek AI: A Peek Under the Hood of This MoE-Powered Beast)) -
挑战
• 路由器设计的复杂性:设计出既高效又稳定的路由器是 MoE 架构的核心挑战,需要在精度、负载均衡与计算效率间取得平衡。
• 大规模专家模型的训练问题:如何在千万级的参数级别下稳定训练多个专家,并使之在反向传播中恰当地更新,是当前研究的重要方向。
• 部分激活策略带来的潜在瓶颈:在某些极端情况下,如果路由器策略不够准确,可能会导致部分专家过载或利用不足,从而影响整体性能。(参见 (On the Benefits of Learning to Route in Mixture-of-Experts Models))
──────────────────────────────
【五、总结】
DeepSeek 的 MoE 架构利用混合专家机制,将庞大参数模型拆分为多个专门化专家网络,并通过高效的路由机制在每次前向传播中仅激活最相关的子网络,从而大幅降低了计算负荷和推理延时。这种架构不仅在模型容量上实现突破,还通过精细化专家分割和共享专家隔离技术提升了模型在多任务下的泛化和灵活性。尽管在实际落地中还需解决路由器设计与负载平衡等挑战,DeepSeek MoE 的成功正在为大语言模型的发展提供新的思路和实践方向。(参见 (DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture …);(deepseek-ai/DeepSeek-MoE: DeepSeekMoE – GitHub))
这种架构不仅提升了整体推理速度,并在逻辑推理、数学计算、代码生成等任务中表现优异,也为未来大规模模型在实际应用中的能耗优化和高效部署提供了技术支撑。(参见 (DeepSeek R1 Now Live With NVIDIA NIM),(Cerebras Launches World’s Fastest DeepSeek R1 Llama-70B …))
总之,DeepSeek 的 MoE 架构以其创新的专家分割、共享专家隔离及高效路由机制,实现了在大规模语言模型中高效利用海量参数计算资源的目标,成为推动下一代高性能深度学习模型的重要技术亮点。
以上概念仍然太复杂 ,如何精简,可否用图示的方法来做
下面用一种简洁的方式和图示方法来说明 DeepSeek 的 MoE 架构。
-
基本概念
──────────────
在传统的 Transformer 模型中,每个 token 都经过统一的网络进行处理;而在 MoE 架构中,整个模型被拆分成多个“专家”(模块),每个专家只专门处理部分信息。核心过程:
• 路由器根据输入 token 的特征,选择出最适合的几个专家。
• 被选中的专家对 token 进行处理,然后将结果反馈回来,完成整体计算。 -
简单图示说明
──────────────
想象一个流程图:
• 输入层:一个 token 输入进来。
• 路由器:负责判断并将 token 分配到不同专家。
• 多个专家模块:分别处理分配给它们的 token。
• 综合输出:各个专家处理结果合并,输出最终结果。
下面是一幅简化的图示,帮助理解 MoE 架构的整体流程:

总之,MoE 架构通过路由器选择部分专家,仅激活最相关的子网络进行计算,从而在保证模型巨大容量的同时降低计算量和提高效率。
需要进一步了解每个部分的详细工作原理吗?
我们可以进一步解析每个部分的详细工作原理,并使用图示来帮助理解。下面将逐一介绍各个模块的工作:
──────────────────────────────
【1. 输入层与 Token 嵌入】
• 输入层负责接受用户的文本输入,并将每个单词或子词映射到向量空间,这个映射称为 Token 嵌入。
• 嵌入后的向量包含了词语的基本语义信息,是后续数据流动的基础。
──────────────────────────────
【2. 路由器(Router)】
• 路由器的任务是分析每个输入 token 的特征,并决定将该 token 分派给哪些专家模块。
• 具体工作原理:
- 对每个 token 的嵌入进行评估,计算各专家的匹配得分。
- 通过 Softmax 或者其他激活函数规范化输出,选择得分最高的几个专家(通常是一到两个)。
- 确保专家之间的负载均衡,避免部分专家过载,而其它专家闲置。
• 路由器的自适应机制确保每次前向传播时,都只激活一部分专家,从而大幅降低计算量。
──────────────────────────────
【3. 专家模块(Experts)】
• 每个专家模块是一个子神经网络,专门负责处理输入 token 中的某部分信息。
• 工作原理:
- 接收来自路由器分配的 token 向量。
- 使用专门训练好的参数进行局部计算,捕捉特定领域或特征模式。
- 返回处理后的特征表示。
• 这种专门化训练能让专家在处理特定类型信息时更高效、更准确。
──────────────────────────────
【4. 合并与输出】
• 将经过各个专家模块处理后的结果进行整合:
- 各专家模块的输出通过加权(根据路由器的分配权重)方式进行组合。
- 整合后的结果传递到后续层(如 Transformer 的后续层或输出层),生成最终的模型预测结果。
──────────────────────────────
【5. 图示说明】
以下是一幅简化的工作流程图,展示了每个部分之间的关系:
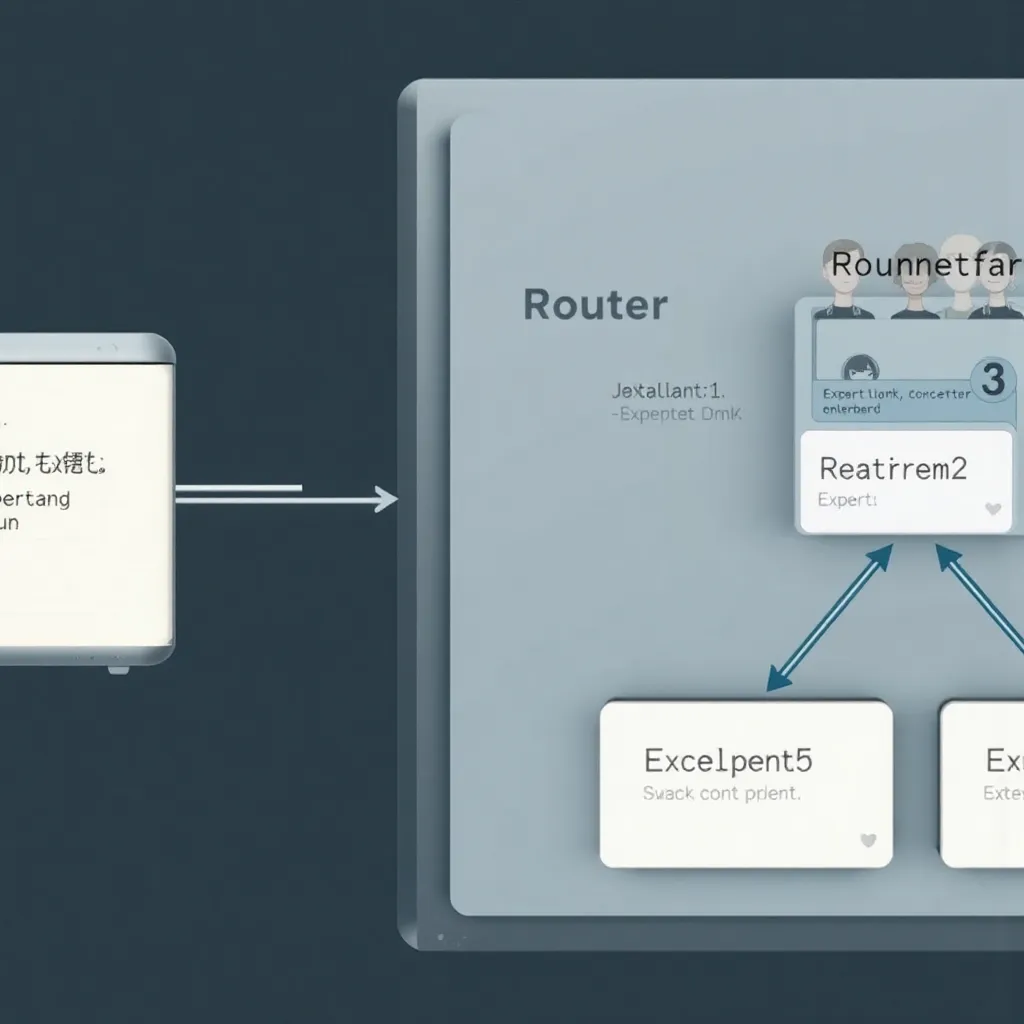
──────────────────────────────
【总结】
通过上述各个部分的协同工作,DeepSeek 的 MoE 架构能够仅激活最相关的专家模块进行计算,这样既充分利用了大模型的海量参数优势,又保持了计算效率和推理速度。希望以上详细解析和图示能帮助你更直观地理解整个模型的工作原理。
#chats





